This one is for my Computer Vision class:
Can You Guess My Drawings? Identify Artists from Artworks
Motivation
Throughout art history, not all artworks are sufficiently valued or even discovered. Sometimes archaeologists or artistic connoisseurs serendipitously find a new artwork but can hardly identify who created it. To identify the artist of artwork, a person needs expertise that they learn from huge amount of artistic and aesthetic training. Thus, we aim to explore whether a machine can accomplish the same task, without extensive study and knowledge of art history. The focus of this project is to take advantage of computer vision and deep learning techniques to extract high-level features from paintings and identify corresponding artists behind particular artworks.
Define the problem
Input: an artistic image.
Output: the probability distribution of artists for the given image,
taking the most probable one as the prediction.

Goal
- Analyze the dataset.
- Preprocess the image data, including data cleansing, data augmentation.
- Train a simple convolutional neural network as a baseline.
- Train classic deep neural network models, including AlexNet, VGG, ResNet, MobileNet, Vision Transformer.
- Evaluate different models on validation dataset and compare corresponding performances.
- Visualize and analyze the results.
What is the insight into the problem that leads to the solution?
- In pixel space, convolution kernels learns spatially related features. Thus, a convolutional neural network is quite suitable for this task.
- In token space, self attention mechanism allows vision transformer learn patch-wisely extracted features. Thus, vision transformer could also address this task.

More details & How it works
- Our convolutional neural network consist of two parts:
- Feature extractor: the feature extractor parts consist of 5 convolution block, in which there are two conv2d layers, each with a relu activation function, followed by a max pooling layer and a batch normalization layer.
- Classifier: a multilayer perceptron.
2. Our vision transformer consist of three parts:
- Patch Embedding: project the image to patches, with embedding and positional coding.
- Transformer Encoder: a multi-layer transformer encoder block that contains self-attention and residual block.
- Classifier: a reduced sum, a layer normalization, and a single linear layer.
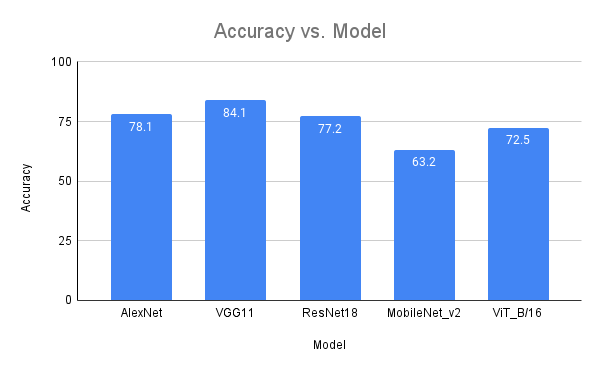
Results (images/figures)