While now full of shitposting and trolling, Baidu Tieba used to be one of the largest and most used Chinese communication platforms. It kind of works like Reddit, as people can create their own forum under different categories.(For more info check https://en.wikipedia.org/wiki/Baidu_Tieba)
It indeed bred a lot of internet subcultures back then. I also had a good and nostalgic memory when I was posting my own fiction and communicating with other people in a really friendly environment back around a decade ago.
This program can be used to crawl the post by entering the URL of that post. It only gets the post from LZ(thread starter) by default, since I would only be needing those posts.
Note that because of the censorship and regulations, some posts containing “sensitive words” might already be deleted. Also Tieba is known for its unstable system because some posts will mysteriously disappear for no reason. There was a wide “system maintenance” that happened in 2019, all the posts back in 2017 can no longer be found, and this news went viral. Many of them were still salvageable and have been restored at this time point, but I can’t guarantee that all the posts are still accessible.
Anyways, let’s get to the code.
I use this post for example: https://tieba.baidu.com/p/1816186611
Code reference: https://www.cnblogs.com/chengxuyuanaa/p/13065178.html
see_lz=1:only the posts from the thread starter(LZ) will be available
pn=1: the page number
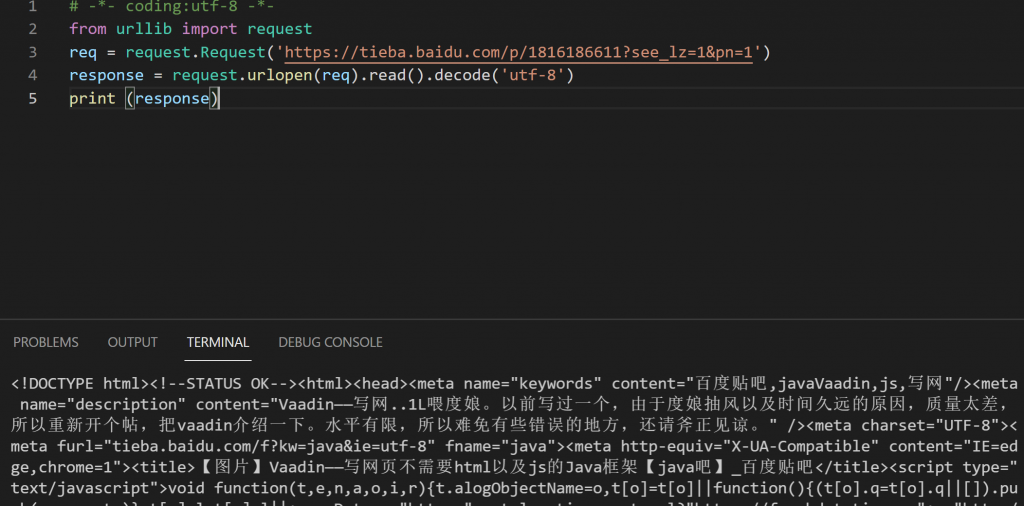
# -*- coding:utf-8 -*-
from urllib import request
req = request.Request('https://tieba.baidu.com/p/1816186611?see_lz=1&pn=1')
response = request.urlopen(req).read().decode('utf-8')
print (response)Note that there are some similar codes online for the same function, but most of them are using ullib2, which will pop error in Python3. To use ulllib2, we would need to install urllib.request and install urllib.error and replace the corresponding code. Change urllib2 to urllib.request and it should work.
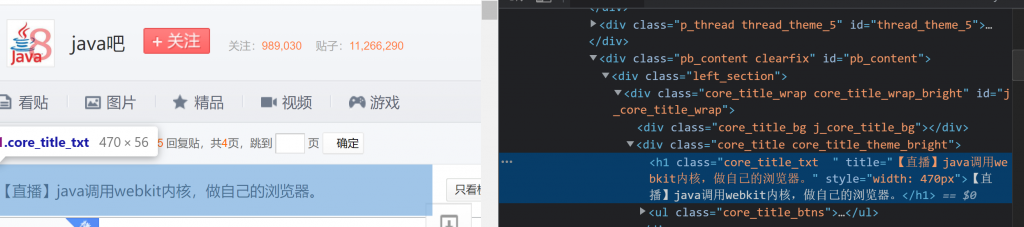
Use the following RE to match the title.
r'<h1 class="core_title_txt.*?>(.*?)</h1>',re.S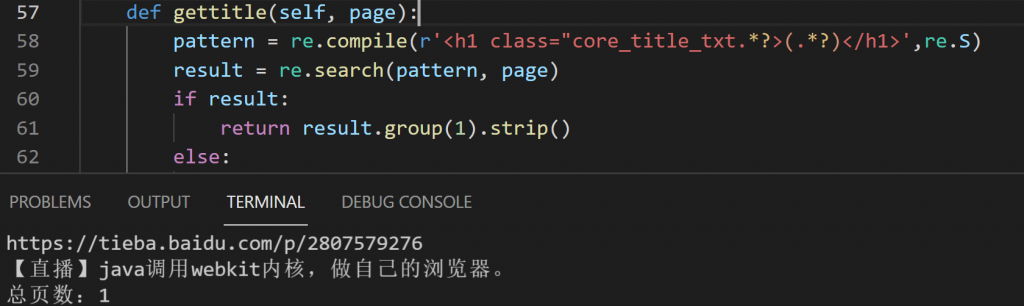
Tieba has changed from GBK to utf-8, but I still encountered problems with Mojibake when opening the .txt

Remember to decode in ‘utf-8’ when requesting the content, and encode also in ‘utf-8’ when writing into txt.
response = request.urlopen(req).read().decode('utf-8', 'ignore')If it prints that the title is None, go check if the code for the header has changed(I have seen both h1 and h3 occur).
If it returned with the error message ‘URL is not valid’, Anti-Spider might be triggered and you might want to wait for a while(at least that is what I did). I personally do not have the need to crawl a massive amount of info from it.
Here is the code that I use. The RE might change throughout the time, so feel free to change accordingly.
# -*- coding: utf-8 -*-
# @Author : TheParnassus
# @Time : 2021/10/30 10:00
# @Function: get Baidu Tieba's post
import os
import re
from urllib import request
class RemoveTags:
# Delete img
removeImg = re.compile('<img.*?>| {7}|')
# delete address
removeAddr = re.compile('<a.*?>|</a>')
# replace tr to \n
replaceLine = re.compile('<tr>|<div>|</div>|</p>')
# replace td to \t
replaceTD= re.compile('<td>')
# replace paragraph with space
replacePara = re.compile('<p.*?>')
# replace linebreak with \n
replaceBR = re.compile('<br><br>|<br>')
# remove other tags
removeOtherTag = re.compile('<.*?>')
def replace(self,x):
x = re.sub(self.removeImg,"",x)
x = re.sub(self.removeAddr,"",x)
x = re.sub(self.replaceLine,"\n",x)
x = re.sub(self.replaceTD,"\t",x)
x = re.sub(self.replacePara,"\n ",x)
x = re.sub(self.replaceBR,"\n",x)
x = re.sub(self.removeOtherTag,"",x)
return x.strip()
class Tieba:
def __init__(self, baseurl, seelz):
# url
self.baseurl = baseurl
# LZ post only = 1 by default
self.seelz = '?see_lz=' + str(seelz)
# removetags
self.removetag = RemoveTags()
def getpage(self, pn):
# get the post in the page(pn)
try:
url = self.baseurl + self.seelz + '&pn=' + str(pn)
req = request.Request(url)
response = request.urlopen(req).read().decode('utf-8', 'ignore')
# return in 'utf-8'
return response
except request.URLError as e:
if hasattr(e, 'reason'):
print('连接失败,错误原因:', e.reason)
return None
def gettitle(self, page):
# get the post title
pattern = re.compile(r'<h3 class="core_title_txt.*?>(.*?)</h3>',re.S)
result = re.search(pattern, page)
if result:
return result.group(1).strip()
else:
return None
def getpagenum(self, page):
# get the page number
pattern = re.compile('<li class="l_reply_num.*?</span>.*?<span.*?>(.*?)</span>',re.S)
result = re.search(pattern, page)
if result:
return result.group(1).strip()
else:
return None
def getcontent(self, page):
# get the post content
pattern = re.compile('<div id="post_content_.*?>(.*?)</div>', re.S)
items = re.findall(pattern, page)
# add filtered contents without tags that are not needed
contents = []
for item in items:
content = "\n" + self.removetag.replace(item) + "\n"
contents.append(content)
return contents
def start(self):
indexpage = self.getpage(1)
pageNum = self.getpagenum(indexpage)
title = self.gettitle(indexpage)
print(title)
# the page does not contain anything
if pageNum is None:
print('URL已失效')
return
print('总页数:%s' % pageNum)
# start a new txt file
with open('test.txt', 'w', encoding='utf-8') as f:
f.write(str(title))
for i in range(1, int(pageNum)+1):
page = self.getpage(i)
contents = self.getcontent(page)
for content in contents:
with open('test.txt', 'a+',encoding='utf-8') as f:
f.write(str(content))
#rename the txt file when done
os.rename('test.txt',((str(title))+ '.txt'))
if __name__ == '__main__':
print ("请输入帖子链接")
baseURL = 'https://tieba.baidu.com/p/' + str(input(u'https://tieba.baidu.com/p/'))
# only thread starter's post will be recorded
seelz = 1
bdtb = Tieba(baseURL, seelz)
bdtb.start()